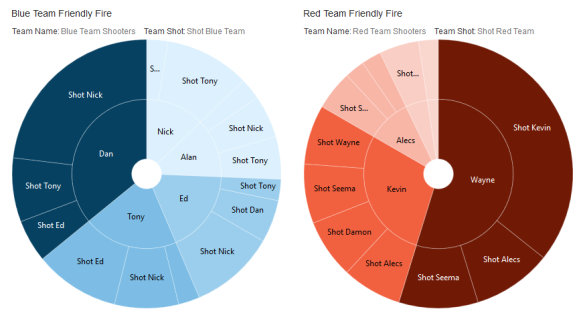
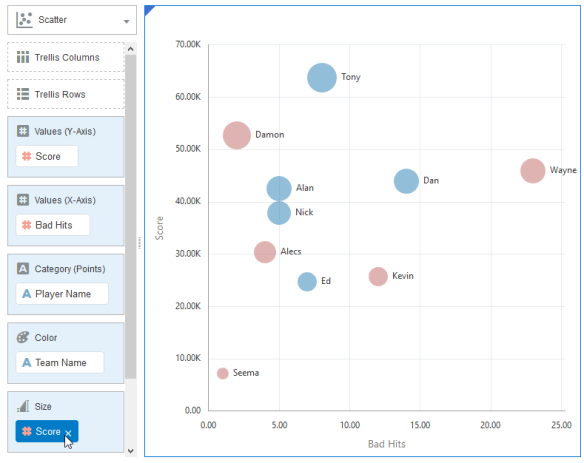
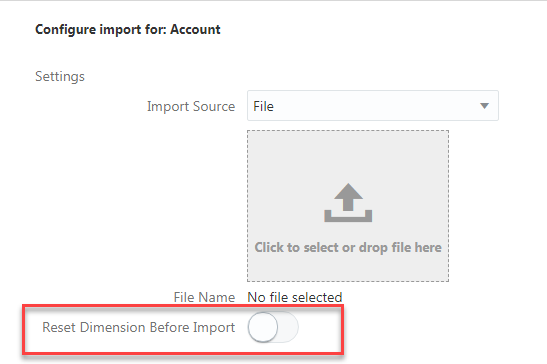
Before forecasting models, before fancy dashboards and pretty reports, before a data point is even considered “Actual” comes the age old question…
“Does this number even look right?”
Bulls*#!
Account reconciliations – the means by which this question is answered – are a fundamental part of the financial close process. Imagine you are trying to build a sandcastle. Now imagine your “sand” is harvested from a cow pasture. You *could* continue to build this “sandcastle,” but you will likely finish with a pile of…bull-sand. In the same way, if your account balances and transactions have an integrity equivalent to “bull-sand,” this will inevitably lead to problems down the line.

The shift to the Cloud has complicated the decision-making process when considering new enterprise-wide application tools. The choice of whether to go with a known “on-premise” solution or take a bold step into Cloud solutions is a daunting one, particularly when considering moving high-visibility cycles such as forecasting or financial consolidations into this brave new world.
A Justified Recommendation
Take the measured move instead. If you feel hesitant to go “all-in” on Cloud offerings, here are four reasons why you should consider entering the Cloud through the arch of ARCS…the ARCSway (Get it?…archway…ARCSway…never mind – just keep reading…)
Safe Bet on a Strong Foundation
Oracle introduced Account Reconciliation Cloud Service (ARCS) as the “one stop shop” solution for managing and streamlining the reconciliation cycle in the Cloud back in 2016. While it’s not uncommon for some EPM products to lose functionality during their initial transition into the Cloud space, ARCS retains the “good bones” of its on-premise counterpart – Account Reconciliation Manager (ARM). ARCS builds upon the clever functionality and customizability of ARM, released in 2012, yet with the slick look and feel of the Oracle Cloud experience.
Since its release, ARCS has become the “golden child” of the reconciliation product family, receiving not only “first dibs” on refinement of existing capabilities, but also benefiting from the newest components such as Transaction Matching (note: this has separate licensing than the Reconciliation Compliance component of ARCS). As the product continues to gain steam, this trend is expected to continue. Between utilizing the tried-and-true foundation of the ARM tool and having Oracle’s watchful eye, ARCS is a safe bet.
No Mistakes with Modularity
Unlike some applications, ARCS is easy to implement in pieces. While good design will certainly prevent future heartache, there are no decisions made on Day 1 of a project that cannot be modified or enhanced in the future:
- Want to manually enter data for reconciliations today, but automatically load them from a source system tomorrow? We can do this.
- Missing fields for additional detail you would like users to include? Can be ready for next period (or the current one even!)
- Only want to rollout in one country to start? No problem – go ahead and make the other entities jealous!
While some changes are “cleaner” than others (I am looking at you, Profile Segments!), ARCS welcomes you to “test the waters” and see what works in your company without needing to go “all-in.” For example, a current client has a live ARM application that provides a viable solution for its reconciliation process needs given the initial project timeline and budget. Although the client wasn’t able to fully utilize the available functionality at the time, the modularity of the reconciliation tools (both ARM and ARCS) allows the opportunity for enhancements without punishing this design decision – we are now revamping the client’s auto-reconciliation setup to further streamline the process. For Partners, this means additional project phases; for clients, this means not biting off more than you can chew (win-win!).
Want to dive deeper into this topic? Read the blog posts in the series Modularity in Account Reconciliation Cloud Service (ARCS): No Mistakes from “Day 1” to “Day 100.”
Fast Implementation Cycles and Rapid ROI
Relative to other EPM project lifecycles, ARCS is typically a quick implementation. As with all projects, there are certainly exceptions, but with Ranzal’s “Quick Start” methodology, we have stood up applications in just six weeks! A strong inventory of project “accelerators” – custom tools and scripts that Ranzal has developed based on common requests across multiple clients – allows sophisticated deployments in a timely manner. Couple this with the inherent time saving benefits of Cloud technology (i.e. lack of infrastructure setup, etc.), and ARCS shines as the first step in a Roadmap, producing tangible metrics for evaluation (ex. completion percentages per period, timeliness per Preparer/Reviewer, reconciliation accuracy, etc.) and giving users a taste of the Oracle Cloud experience in a short period of time.
You Don’t Have Anything Today and It’s Costing You
I know that may read like a presumptuous fear tactic, but hear me out:
Account reconciliations ARE being completed in your company – one way or another. Whether that means your CPAs are *click*click* clicking away on their keyboards to manually update Excel spreadsheets or – heaven forbid – actually printing out recons to hand sign, if you cannot name the system that is comprehensively handling your reconciliation cycle, it’s because there isn’t one.
And this is normal. But there are costs associated with this normalcy.
Reconciliation cycles aren’t sexy (well…personal taste…) and often have low visibility to upper management. And yet (!) the reconciliation process is often widespread across the company spanning business entities, departments, and corporate ladders (I see you, Mr/s. Director signing off on recons). ARCS is an attractive option when considering enterprise-wide Cloud solutions to “test run” because everyone can try it. A successful ARCS implementation paves the way for easier adoption of future projects – it gets everybody onboard.
Step Through the “ARCSway” and Ditch the Bulls*#!
The shift to the Cloud is disrupting the traditional market of on-premise EPM solutions. As you look at the new strategic options available to your company’s roadmap, consider ARCS as a “first step.” Of note, it is important to have an accurate understanding of the tool – ARCS is first and foremost a management tool, and although it can provide helpful information in troubleshooting account variances, it does not replace actually performing a reconciliation in an ERP system. Additionally, customizing reports can be difficult (unless you are familiar with BI Publisher), although the out-of-the-box reports and strong dashboarding capabilities largely make up for this limitation. All-in-all, I strongly recommend this product as an introduction to the new Oracle offerings. ARCS’ “low risk, high reward” nature provides real company value quickly while presenting you with a good picture of life in the Cloud. Now is the perfect time to ditch your “bull-sand” reconciliation process and update to a more solid foundation in the Cloud through the ARCSway.
Contact us today for details about a custom Cloud solution for your business needs.


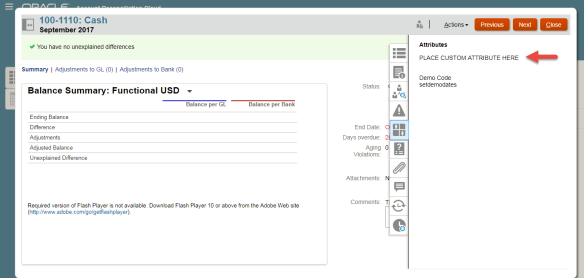 [Screenshot 2: Custom Attribute on the Summary tab*]
[Screenshot 2: Custom Attribute on the Summary tab*]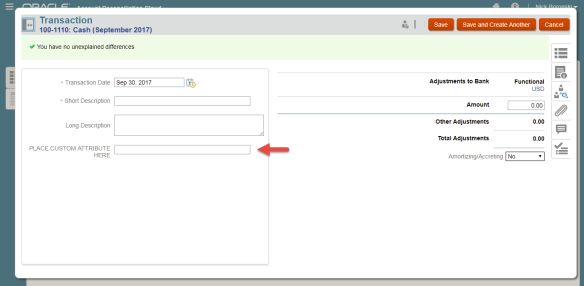 [Screenshot 3: Custom Attribute on a Transaction*]
[Screenshot 3: Custom Attribute on a Transaction*]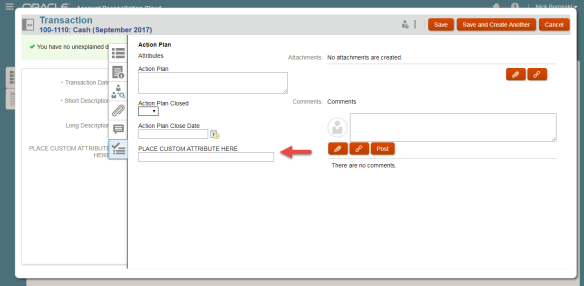 [Screenshot 4: Custom Attribute on an Action Plan*]
[Screenshot 4: Custom Attribute on an Action Plan*]